1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
|
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
from gensim.models import KeyedVectors
import datetime
TRAIN_TEXT = './data/新闻标题分类Train.txt'
TEST_TEXT = './data/新闻标题分类Test.txt'
#人民日报预训练字向量
EMBEDDINGD_DIR = '../Word_Embeddings/sgns.renmin.bigram-char'
embedding = KeyedVectors.load_word2vec_format(EMBEDDINGD_DIR, binary=False,limit=50000)
def word_to_vector(words_array, words_embedding, max_len=30):
'''
将字转为字嵌入,words_array为一维数组,每个元素是一句话
'''
words_vector = []
i = 0
for sentence in words_array:
if max_len != None:
current_vector = np.zeros((max_len,300),dtype = np.float32)
else:
current_vector = np.zeros((len(sentence), 300), dtype = np.float32)
# print(current_vector.shape)
index = 0
for word in sentence:
try:
current_vector[index] = words_embedding[word]
index += 1
if index == max_len:
break
except:
#可能会出现某个字在embedding中不存在的情况,则跳过这个字
continue
#end for
words_vector.append(current_vector)
# print(words_vector.shape)
# break
#end for
return np.array(words_vector)
def read_data(train_text):
'''
读取训练文件,并划分训练集和测试集
'''
category = []
news_data = []
news_label = []
with open(train_text,'r', encoding='utf-8') as f:
lines = f.readlines()
current_category = int('0')
category.append([current_category, '财经'])
#['0', '财经', '上证50ETF净申购突增\n']
#每个类别保留的最大样本数目,防止内存爆炸
count = 0
max_keep = 50000
for line in lines:
line = line.strip().split('\t')
cate = int(line[0])
#还是当前类,但是count已经到达最大max_keep,不处理
if cate == current_category and count >= max_keep:
continue
if cate != current_category:
# print(count)
current_category = cate
category.append([current_category, line[1]])
count = 0
news_data.append(line[2])
news_label.append(cate)
count += 1
news_data = np.array(news_data)
news_label = np.array(news_label)
#划分训练集和测试集
n = len(news_data)
sample_index = np.random.permutation(n).astype(np.int32)
train_index = sample_index[ : int(n * 0.93)]
test_index = sample_index[int(n * 0.93) : ]
train_data = news_data[train_index]
train_label = news_label[train_index]
test_data = news_data[test_index]
test_label = news_label[test_index]
return np.array(category), train_data, train_label, test_data,test_label
#取出第一类作为正样本,再从其余类中取出负样本
def get_category_sample(category_id, data, label, batch_size=None):
'''
取出一个类作为正样本,再从其余类中随机选出和正样本数量相当的负样本,尽可能包含所有类
'''
pos_sample_index = []
other_sample_index = []
n = len(label)
for index in range(n):
if category_id == label[index]:
pos_sample_index.append(index)
else:
other_sample_index.append(index)
#正样本个数
pos_n = len(pos_sample_index)
#随机取跟正样本数量一样的负样本
neg_sample_index = np.random.choice(other_sample_index, size=pos_n, replace=False)
#将正负样本的index拼接并打乱顺序
sample_index = np.concatenate((pos_sample_index, neg_sample_index)).astype(np.int32)
np.random.shuffle(sample_index)
#用sample_index取出样本
n = len(sample_index)
train_index = sample_index[ : int(n * 0.9)]
test_index = sample_index[int(n * 0.9) : ]
train_data = data[train_index]
train_label = label[train_index]
# print(train_index.shape)
test_data = data[test_index]
test_label = label[test_index]
#将当前类的label设置为1,其他类设置为0
def change_label(lab):
n = len(lab)
for i in range(n):
if lab[i] == category_id:
lab[i] = 1
else:
lab[i] = 0
return lab
train_label = change_label(train_label)
test_label = change_label(test_label)
return train_data, train_label, test_data, test_label
#统计标题长度
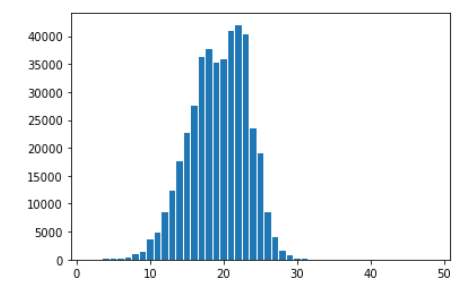
def count_len(data):
max_len = 0
n = len(data)
len_dict = {}
for i in range(n):
sentence_len = len(data[i])
if sentence_len in len_dict:
len_dict[sentence_len] += 1
else:
len_dict[sentence_len] = 1
lengths = [key for key in len_dict.keys()]
lengths.sort()
count = [len_dict[key] for key in lengths]
plt.bar(lengths, count)
plt.show()
#二分类模型
class BinaryClassifyModel(tf.keras.Model):
def __init__(self,filters=196, kernel_size=4):
super().__init__()
self.conv1 = tf.keras.layers.Conv1D(filters, kernel_size, strides=2, activation='relu')
self.maxpool1 = tf.keras.layers.MaxPool1D(strides=2)
self.conv2 = tf.keras.layers.Conv1D(filters=64, kernel_size=3, activation='relu')
self.maxpool2 = tf.keras.layers.MaxPool1D(strides=2)
self.fc1 = tf.keras.layers.Dense(128, activation='relu')
self.fc2 = tf.keras.layers.Dense(64, activation='relu')
self.fc3 = tf.keras.layers.Dense(1, activation='sigmoid')
def call(self, inputs):
#卷积层
x = self.conv1(inputs) #shape: batch_size,new_steps(stpe / strides (- 1)), filters ,(batch_size, 14 ,196)
x = self.maxpool1(x) #(batch_size,7, 196)
x = self.conv2(x) #(batch_size,5, 64)
x = self.maxpool2(x) #(batch_size,2, 64)
#将三维向量reshape为二维矩阵,用于全连接层输入
x = tf.reshape(x, (tf.shape(x)[0], -1)) #(batch_size, 128)
# print(x.shape)
#全连接层
x = self.fc1(x)
x = self.fc2(x)
# output = tf.nn.softmax(self.fc3(x))
output = self.fc3(x)
return tf.reshape(output, [output.shape[0]])
def train_a_classifier(train_vector,train_label, model, save_dir,learning_rate=0.001, msg=''):
'''
训练一个模型,
'''
train_iterator = tf.data.Dataset.from_tensor_slices((train_vector, train_label)).batch(BATCH_SIZE).repeat(EPOCH)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
check_point = tf.train.Checkpoint(binary_model = model)
checkpoint_manager = tf.train.CheckpointManager(check_point, directory=save_dir, max_to_keep=1)
acc_ary = []
loss_ary = []
steps = []
with tf.device('/gpu:0'):
for step,(x, y) in enumerate(train_iterator):
with tf.GradientTape() as tape:
y_pred = model(x)
#损失函数,二分类交叉熵
loss = tf.keras.losses.binary_crossentropy(y_pred=y_pred, y_true=y)
loss = tf.reduce_mean(loss)
#计算正确率
y_pred = tf.where(y_pred < 0.5, x=tf.zeros_like(y_pred), y=tf.ones_like(y_pred))
y_pred = y_pred.numpy().astype(np.int32)
train_acc = np.sum(y_pred == y) / y.shape[0]
# print(y_pred)
# print(y)
# print(train_acc)
# break
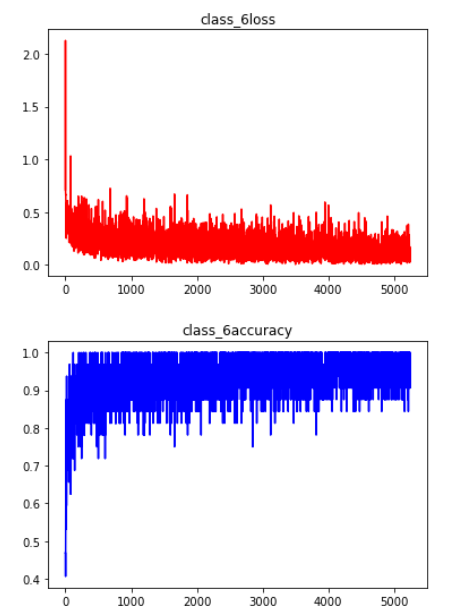
#统计损失和正确率,用于画图
loss_ary.append(loss.numpy())
acc_ary.append(train_acc)
steps.append(step)
grads = tape.gradient(loss, model.variables)
optimizer.apply_gradients(grads_and_vars= zip(grads, model.variables))
if step % 200 == 0:
print("{} setp: {} , loss : {} , train acc : {}".format(msg, step, loss, train_acc))
plt.plot(steps, loss_ary, c='r')
plt.title(msg + 'loss')
plt.show()
plt.plot(steps, acc_ary, c='b')
plt.title(msg + 'accuracy')
plt.show()
path = checkpoint_manager.save()
print('保存模型到:{}'.format(path))
return model
def train_all_classifier(category, train_data, train_label):
'''
训练所有分类器
categroy:二维数组,第一列为category_id, 第列为id对应的名称
train_data,train_laber:所有类别的训练数据和标签,都是一维数组,一个元素为一句话或一个标签
'''
models_list = []
models_save_dir = []
# print(train_data.shape)
for cate in category:
model = BinaryClassifyModel()
category_id = int(cate[0])
print('当前训练:{}'.format(category_id))
start_time = datetime.datetime.now()
data_train, label_train, data_test, label_test = get_category_sample(category_id, train_data, train_label)
train_vector = word_to_vector(data_train, embedding, max_len=30)
print('准备数据用时:{}'.format(datetime.datetime.now() - start_time))
# test_vector = word_to_vector(data_test, embedding, max_len=30)
#MODEL_SAVE_DIR命名规则,MODEL_SAVE_DIR + category_id,如./model_save/class_1,./model_save/class_2
model = train_a_classifier(train_vector, label_train, model,save_dir=MODEL_SAVE_DIR + str(category_id), learning_rate=LEARNING_RATE, msg='class_'+str(category_id))
print('训练用时:{}'.format(datetime.datetime.now() - start_time))
models_list.append(model)
def test_all_classifier(category, test_data, test_laber, need_load_checkpoint=False, model_ary=None):
'''
测试所有分类器的性能
'''
start_time = datetime.datetime.now()
test_vector = word_to_vector(test_data, embedding, max_len=30)
print('准备数据用时:{}'.format(datetime.datetime.now() - start_time))
#从文件中加载训练好的模型
if need_load_checkpoint:
model_ary = []
for cate in category:
category_id = int(cate[0])
model = BinaryClassifyModel()
check_point = tf.train.Checkpoint(binary_model = model)
check_point.restore(tf.train.latest_checkpoint(MODEL_SAVE_DIR + str(category_id)))
model_ary.append(model)
start_time = datetime.datetime.now()
test_iterator = tf.data.Dataset.from_tensor_slices((test_vector, test_label)).batch(BATCH_SIZE)
acc_ary = []
count = 0
with tf.device('/gpu:0'):
for x,y in test_iterator:
class_probability = []
n = len(model_ary)
#测试样本依次通过每个二分类分类器,并记录下是该类的概率,哪个分类器的输出概率最大,则认为是哪个类
for i in range(n):
y_pro = model_ary[i](x)
class_probability.append(y_pro)
y_pred = tf.argmax(class_probability, axis=0).numpy().astype(np.int32)
test_acc = np.sum(y_pred == y) / y.shape[0]
acc_ary.append(test_acc)
count += y.shape[0]
#endfor
#end with
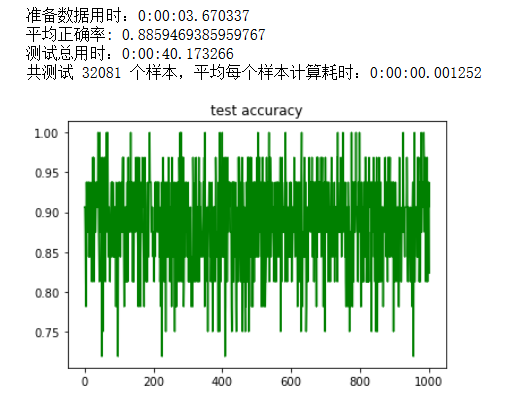
end_time = datetime.datetime.now()
print('平均正确率: {}'.format(np.average(acc_ary)))
print('测试总用时:{}'.format(end_time - start_time))
print('共测试 {} 个样本,平均每个样本计算耗时:{}'.format(count, (end_time - start_time) / count))
plt.plot(np.arange(0, len(acc_ary)), acc_ary, c='g')
plt.title('test accuracy')
plt.show()
BATCH_SIZE = 32
EPOCH = 2
LEARNING_RATE = 0.005
LOG_DIR = './model_log'
MODEL_SAVE_DIR = './model_save/class_'
#读取训练数据
category, train_data, train_label, test_data,test_label = read_data(TRAIN_TEXT)
#统计句子长度,确定最长序列
count_len(train_data)
#训练所有分类器
start_time = datetime.datetime.now()
models_list = train_all_classifier(category, train_data, train_label)
end_time = datetime.datetime.now()
print('训练总用时:{}'.format(end_time - start_time))
#测试所有分类器
test_all_classifier(category, test_data, test_label,need_load_checkpoint=True)
|